TL;DR
Energy-Based Transformers (EBTs) outscale (feed-forward) transformers while generalizing reasoning/system 2 thinking to any modality/problem without requiring verifiable rewards! EBTs are the first approach to outscale feed-forward transformers across modalities and with respect to several axes including data, depth, parameters, FLOPs, etc. EBTs can also think over every single prediction being made (i.e. every token in language modeling) and generalize better than existing models.
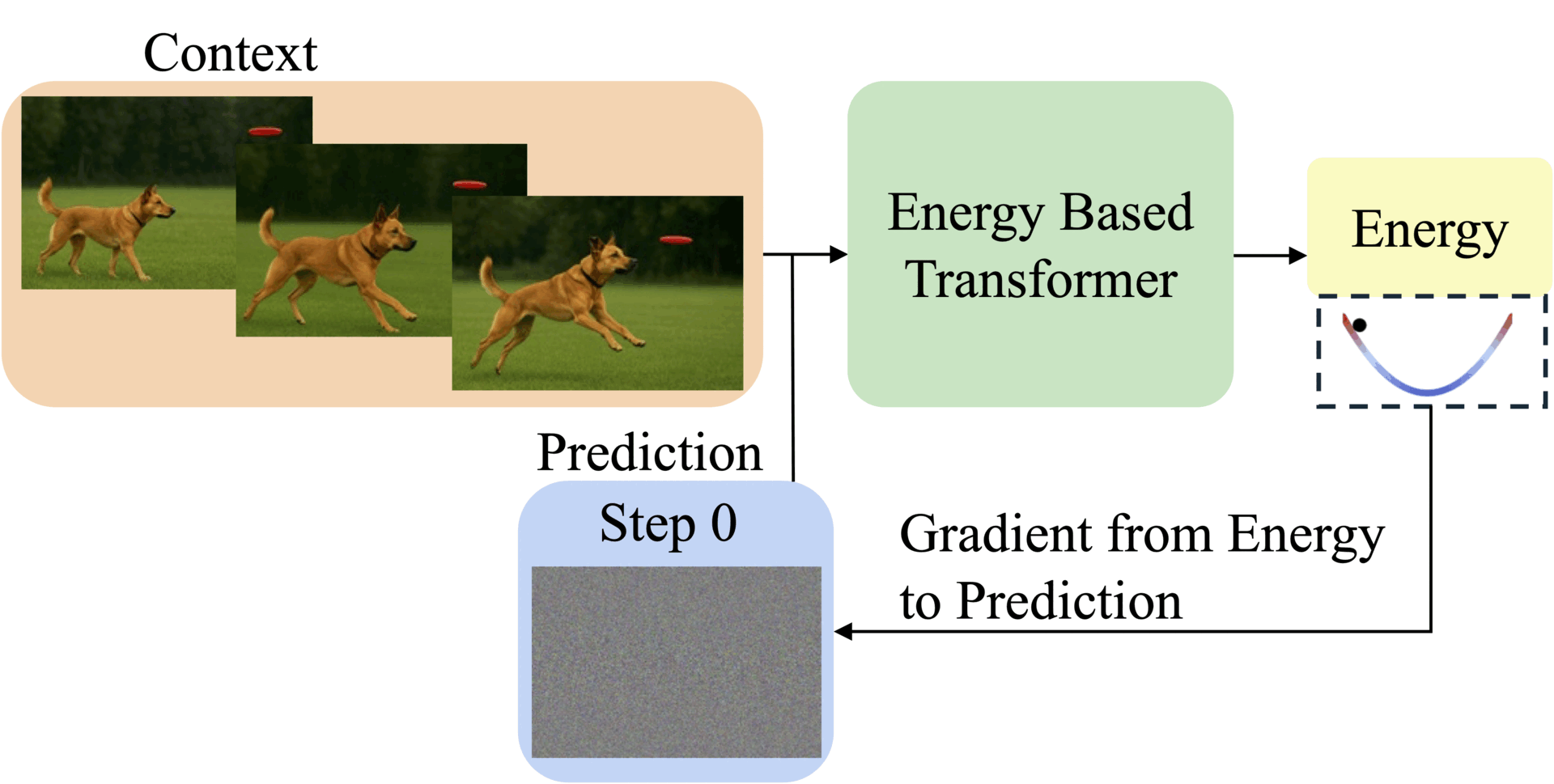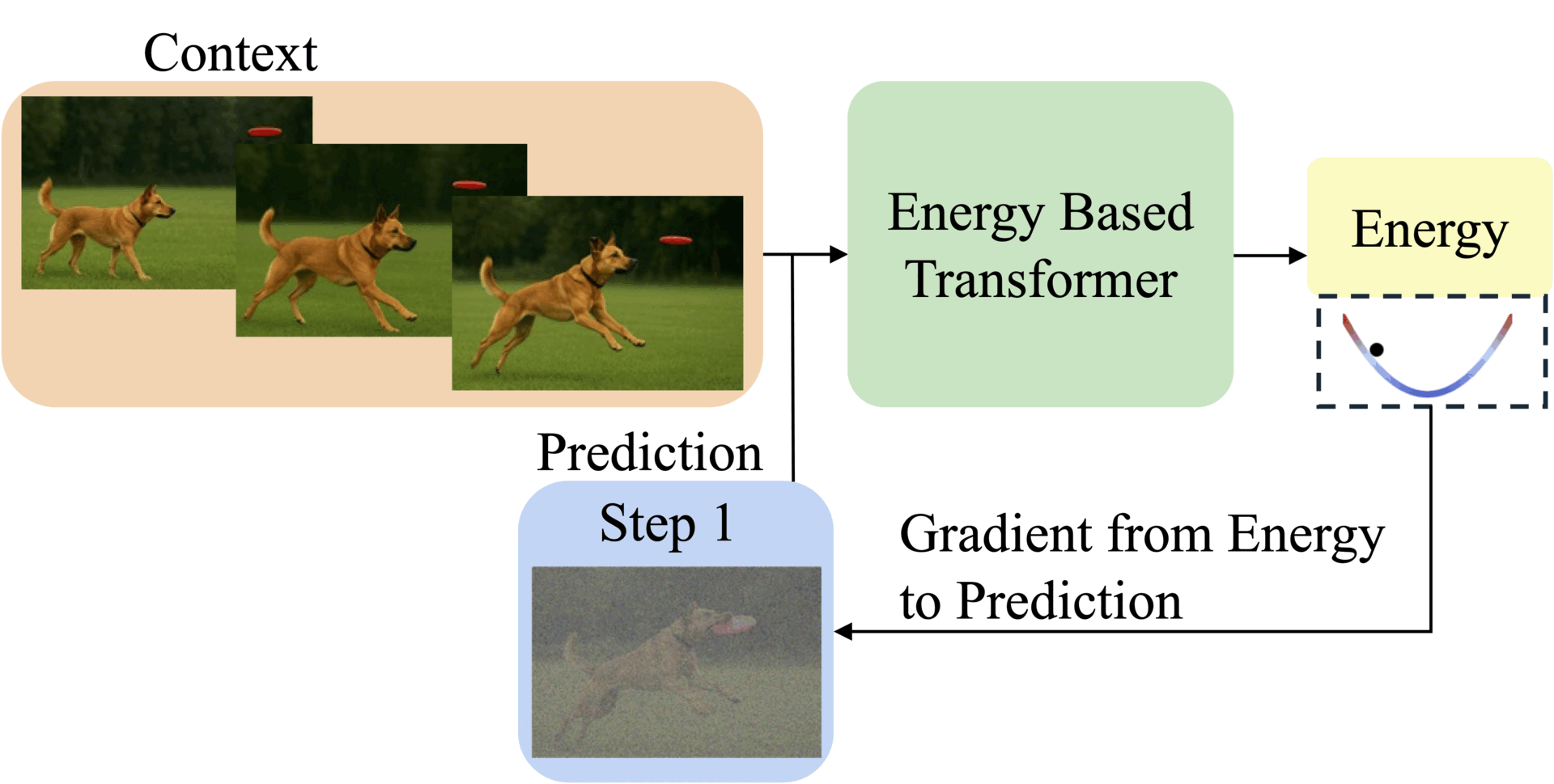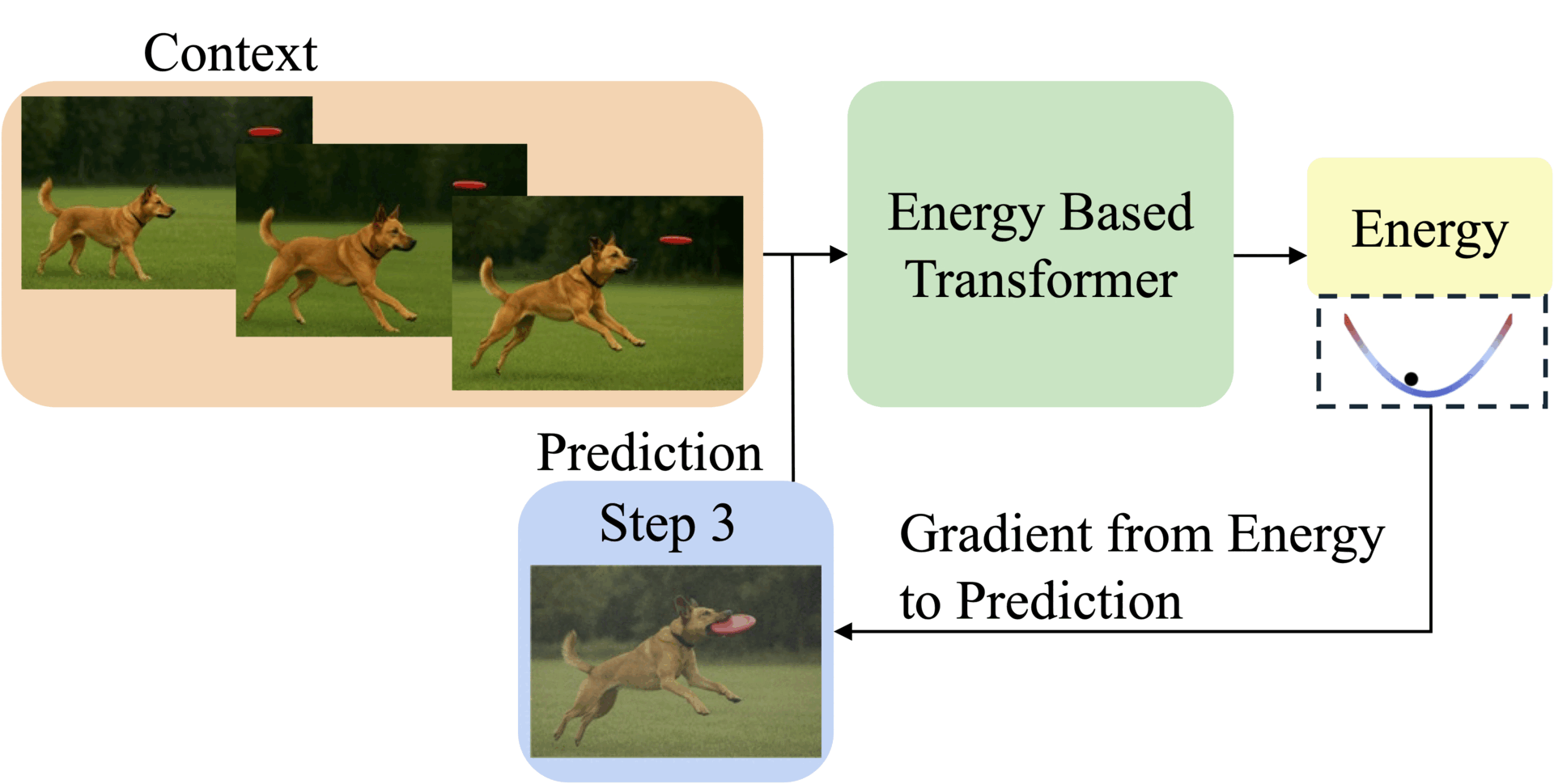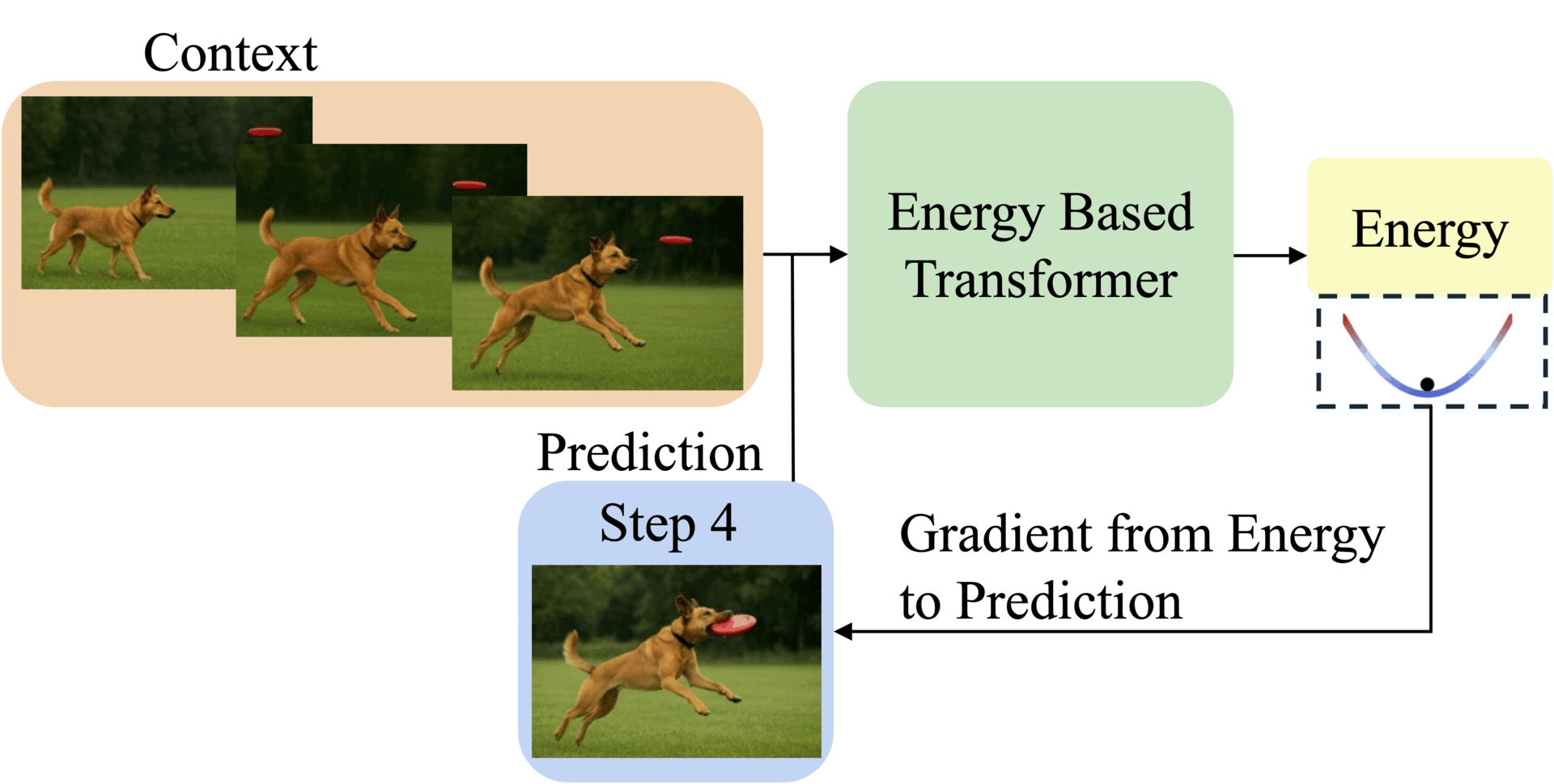
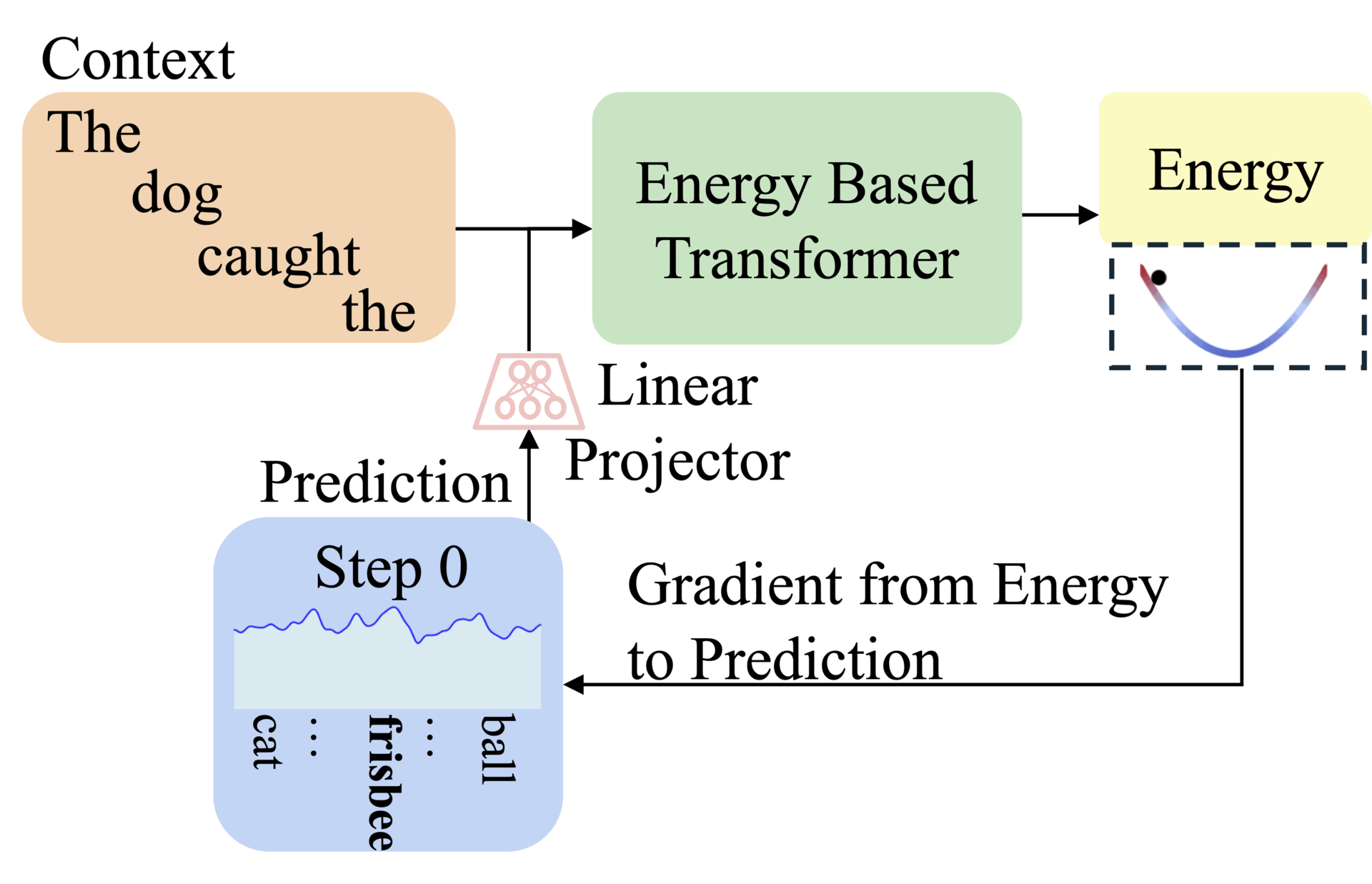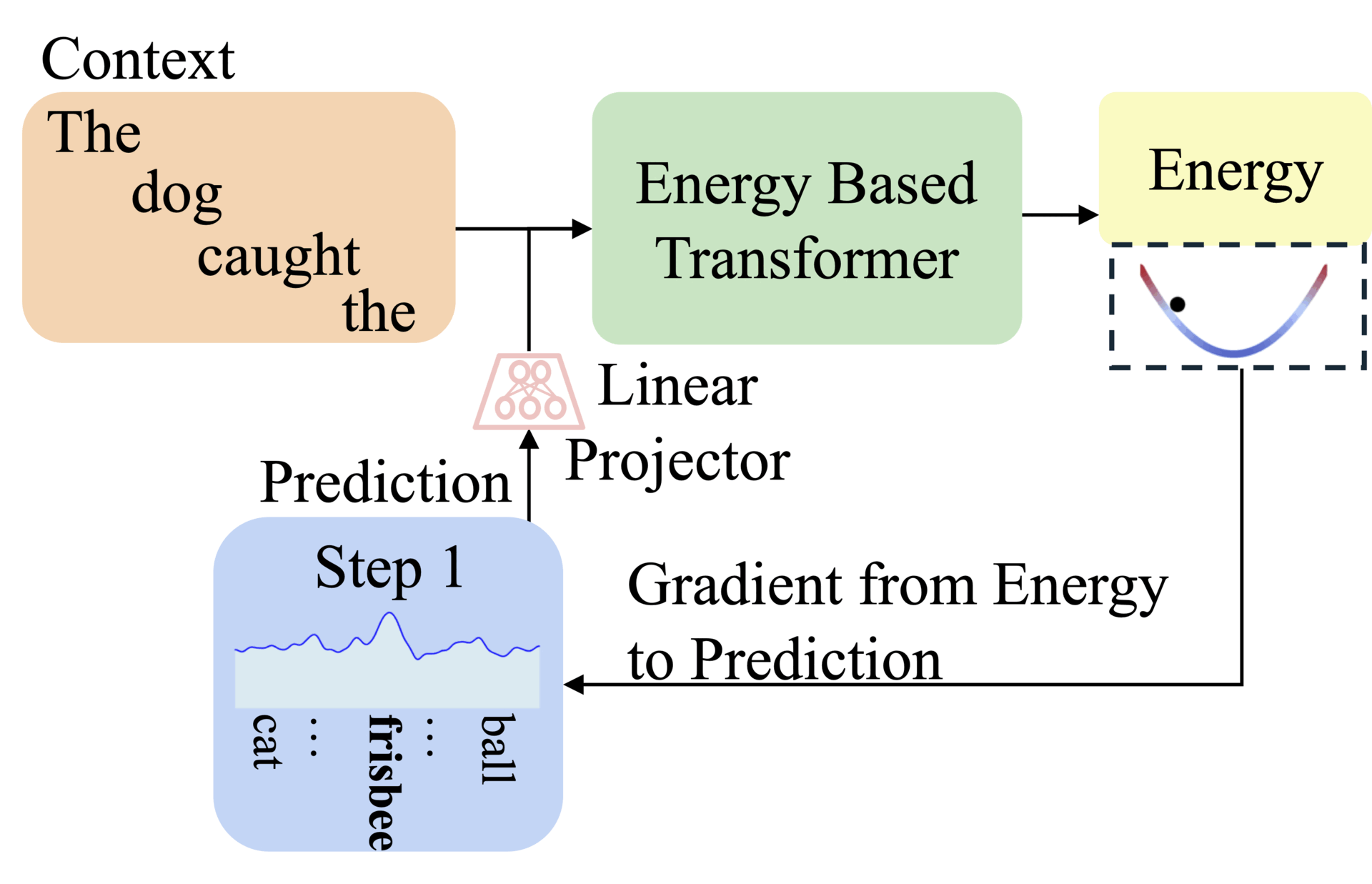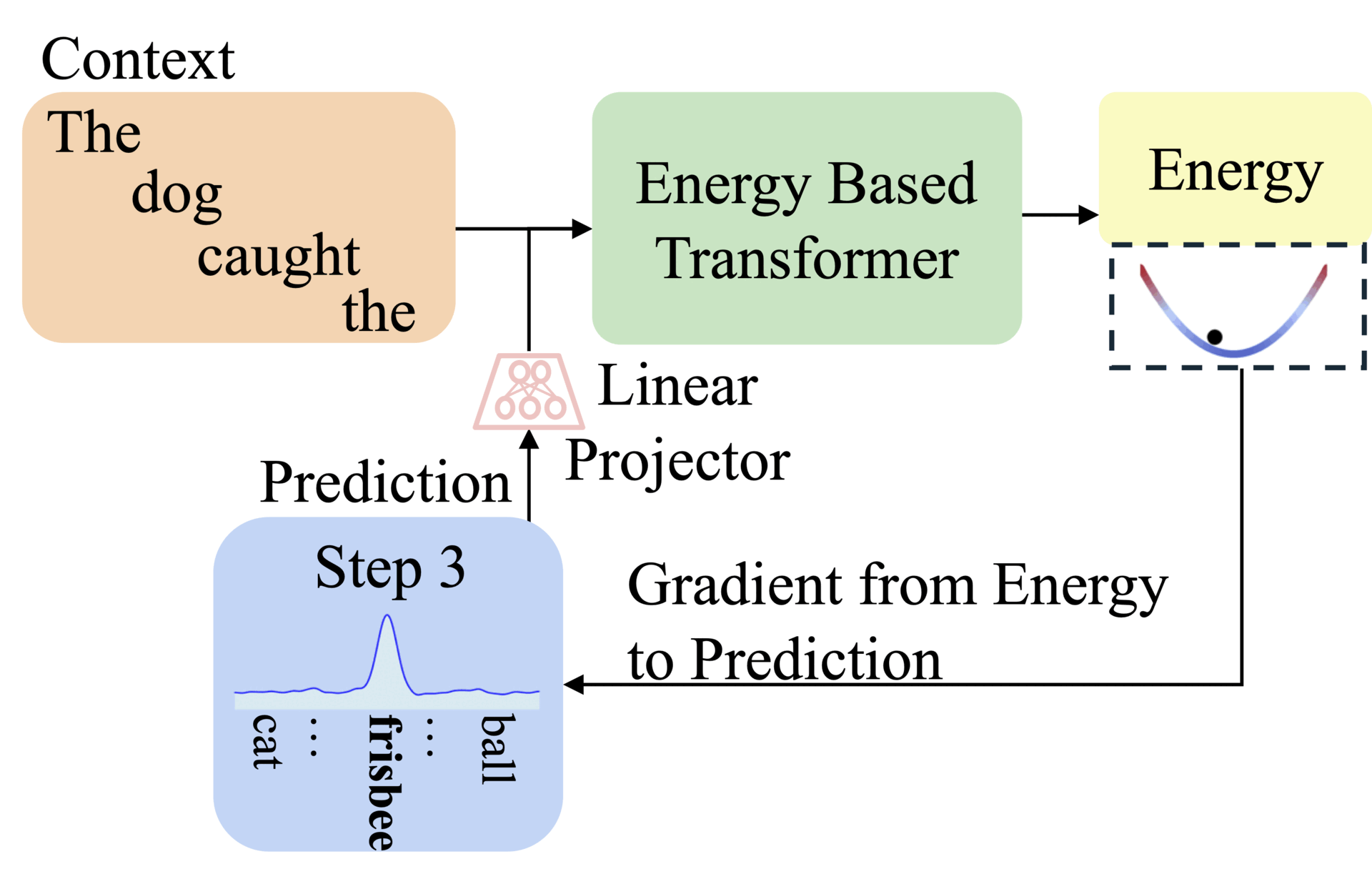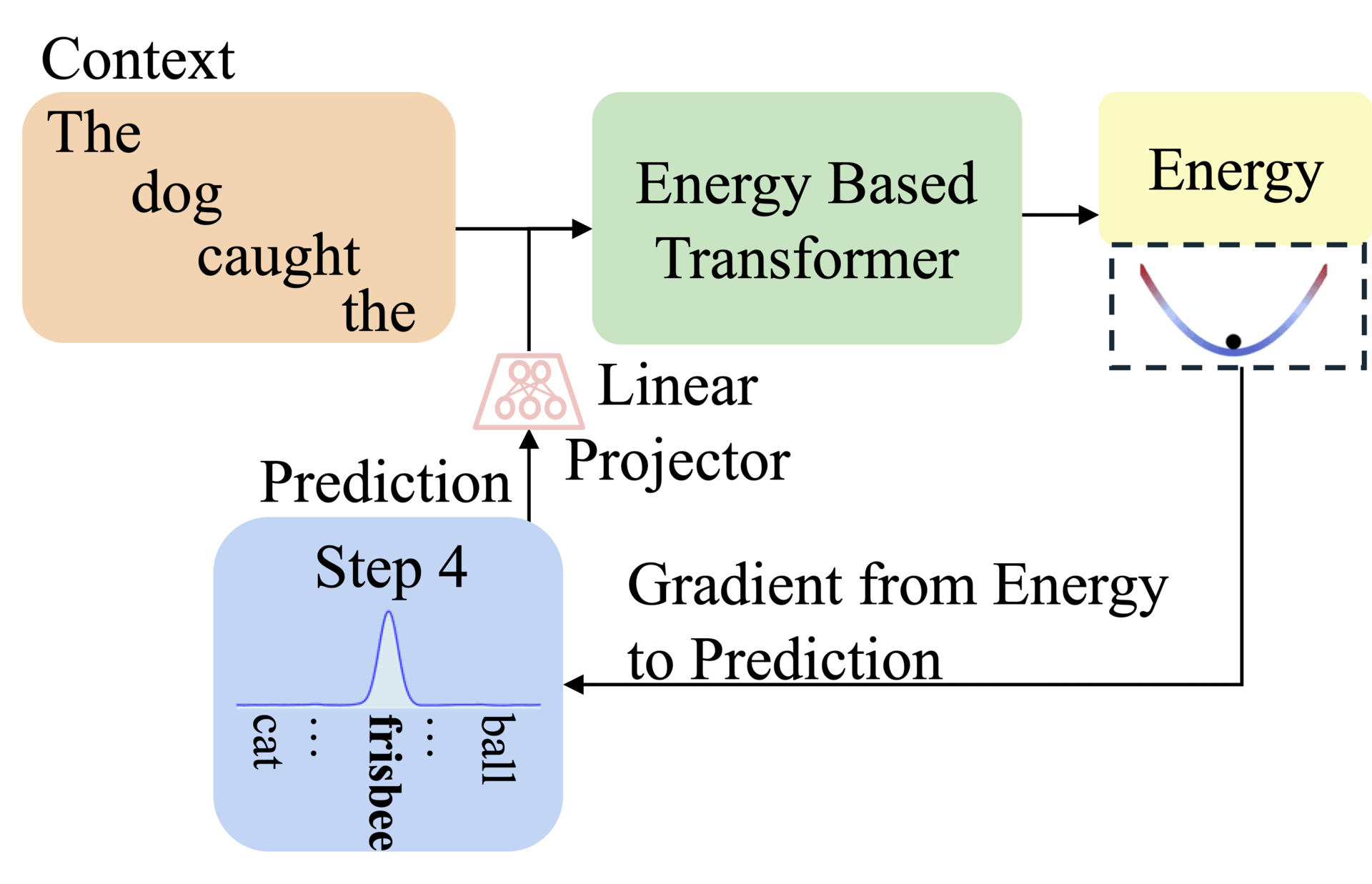
Abstract
BibTeX
@misc{gladstone2025energybasedtransformersscalablelearners,
title={Energy-Based Transformers are Scalable Learners and Thinkers},
author={Alexi Gladstone and Ganesh Nanduru and Md Mofijul Islam and Peixuan Han and Hyeonjeong Ha and Aman Chadha and Yilun Du and Heng Ji and Jundong Li and Tariq Iqbal},
year={2025},
eprint={2507.02092},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2507.02092}
}